An howto on installing CloudFoundy on Windows using Bosh-lite….
OCR with Java and Tesseract
Introduction
Ever wanted to scan (OCR) a document from an application? You may want to take a look at Tesseract. Tesseract is ocr engine once developed by HP. Currently it is an opensource project sponsored by Google. The software is capable of taking a tiff picture and transforming it into text. It supports a wide range of languages and fonts. Tesseract is a rather advanced engine. Unlike some of the available cloud based OCR services, it for example provides the option to get information on location of each word found on a page. This is important if you want to parse the fetched text.
The engine is written in C++. This makes it somewhat hard to use it from Java. Fortunately there is Java ‘wrapper’ available named Tess4J. Tess4J also provides the option to scan pdf documents next to tiffs. This document provides a ‘howto’ for use of Tess4J on Windows.
Step 1: Preparation
Introduction
As a first step download the following software:
- Visual C++ Redistributable for VS2012. This library is required.
- Eclipse. I used the 32 bit version o Eclipse for EE.
- Tess4J java API
- Language data packs. The language pack for English is included in Tess4J. If you required other languages, download these.
- GPL Ghostscript. Ghostscript is required for PDF support.
You may wonder why you don’t need to download the Tesseract Engine itself…. the reason is simple. It comes with Tess4J. By the way, this is not the fact when you use Tess4J on Linux. In that case you need to download and install Tesseract.
Step 2: Install the software
3.1: Install the visual C++ Redistributable.
3.2: Install Eclipse
3.3: install GPL Ghostscript. Make sure the bin directory within the installation directory is added to the PATH (this doesn’t seem to happen automatically).
3.4: install Tess4J.
3.5: Extract the language training data. The language training files are provided in the tar.gz format. For example the Dutch training files are downloaded as tesseract-ocr-3.02.nld.tar.gz. Unzipt the tar.gz (use 7zip). Unzip the file <country identifier>.traineddata (for example nld.traineddata for Dutch) to <Tess4J directory>\tessdata (in my case C:\bin\Tess4J\tessdata\). You will find the English language file in this directory already.
Step 3: Create a test application in Eclipse
3.1: Create a new java project named Tess4JTest
a) Click File –> new –> other
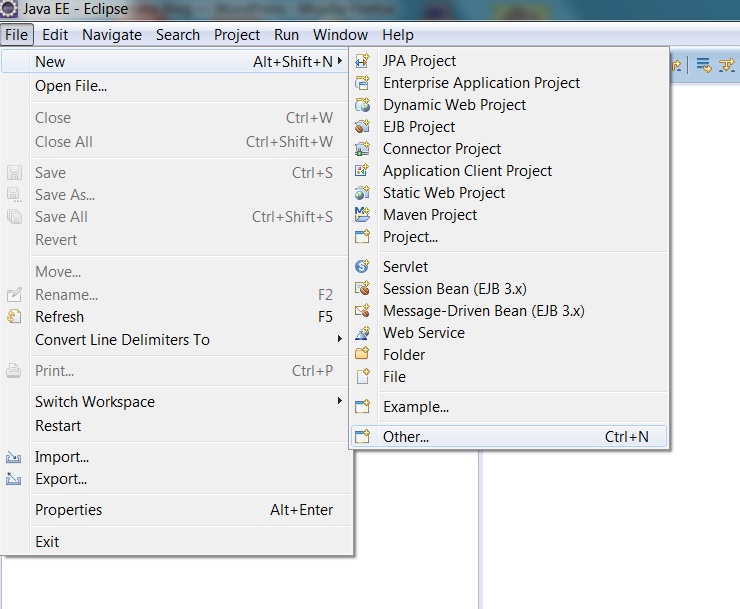
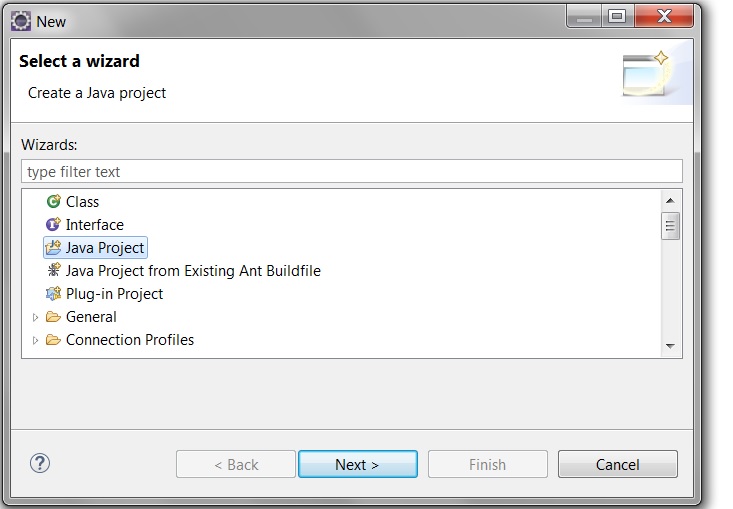
b) Select ‘Java Project’ and click ‘next’.
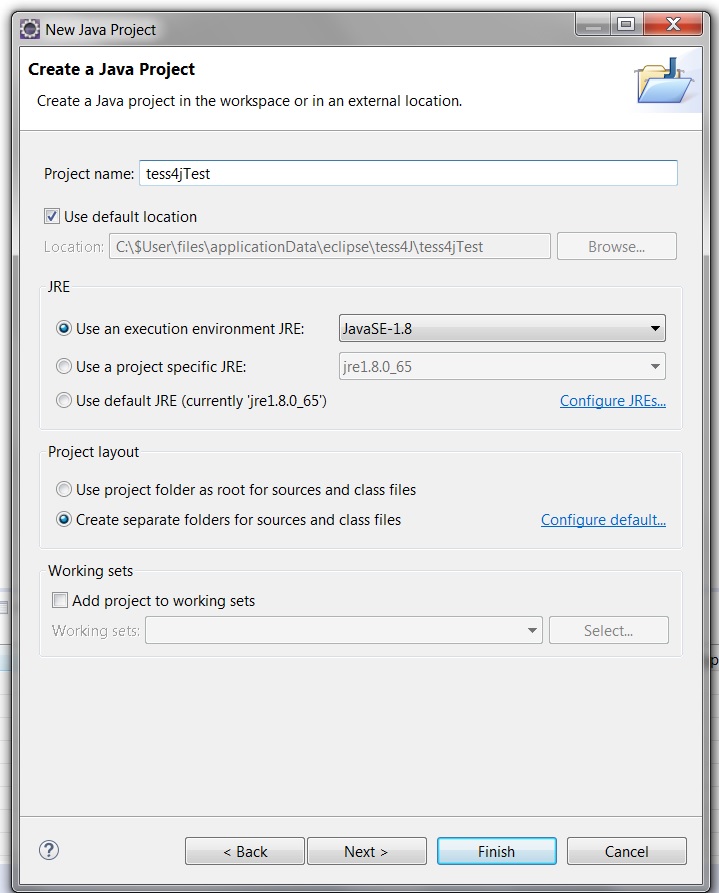
c) Enter Tess4J as a Project Name and click Finish.
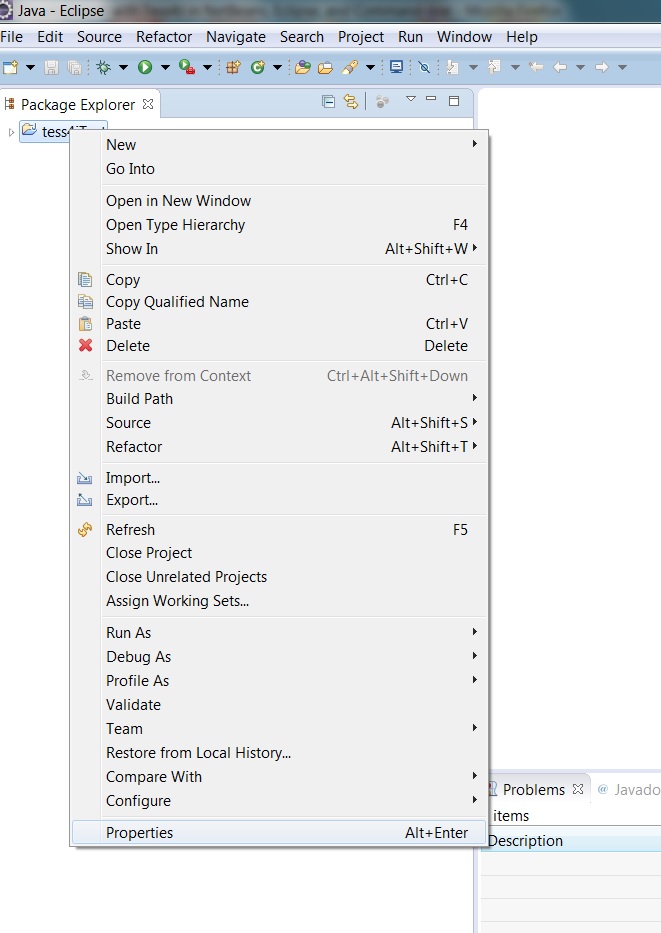
3.2: Import the required jars.
a) Right click the Tess4J project and select ‘Properties’.
b) Select Java build path –> Libraries
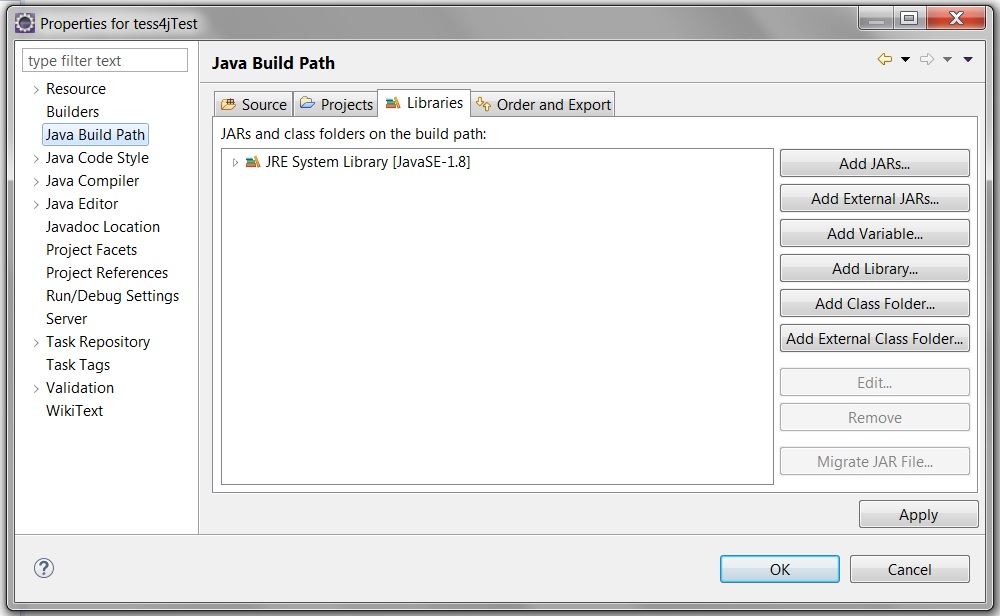
c) Click ‘Add External Jar’
d) Select the following jars: jai_imageio.jar, jna.jar, commons-io-2.4.jar, Ghost4j-0.5.1.jar, log4j-1.2.17 and tess4j.jar (from C:\bin\Tess4J\lib and C:\bin\Tess4J\dist).
e) Create a new java class named ‘TestTess.java’ by clicking file->new->class
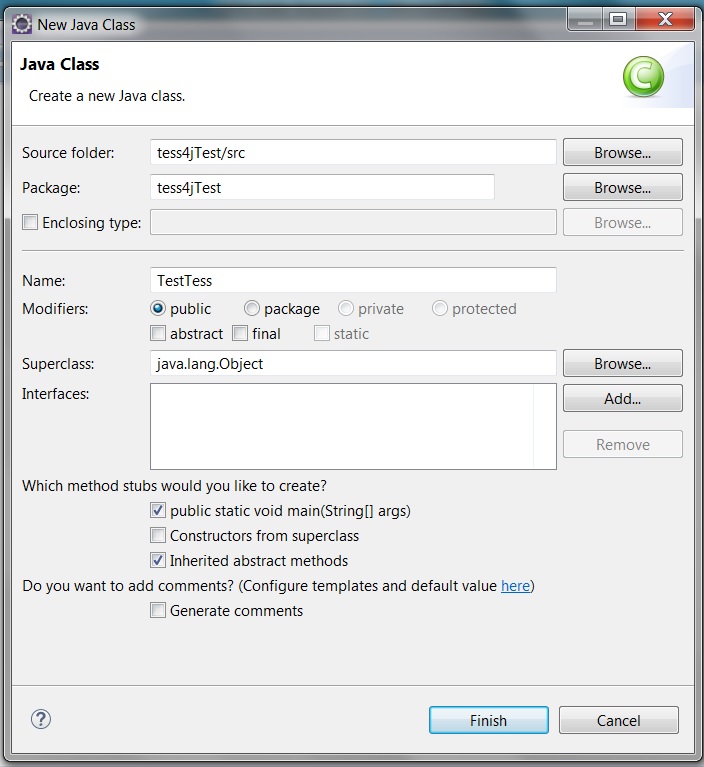
f) Create the following java class:
package tess4jTest;
import java.io.File;
import net.sourceforge.tess4j.*;
public class Testtess {
public static void main(String[] args) {
File image = new File("C:/bin/Tess4J/eurotext.tif");
Tesseract tessInst = new Tesseract();
tessInst.setDatapath("C://bin//Tess4J");
try {
String result= tessInst.doOCR(image);
System.out.println(result);
} catch (TesseractException e) {
System.err.println(e.getMessage());
}
}
}
g) The console will show something like this:
The (quick) [brown] {fox} jumps!
Over the $43,456.78 <lazy> #90 dog
& duck/goose, as 12.5% of E-mail
from aspammer@website.com is spam.
Der ,,schnelle” braune Fuchs springt
?ber den faulen Hund. Le renard brun
«rapide» saute par-dessus le chien
paresseux. La volpe marrone rapida
salta sopra i] cane pigro. El zorro
marrén répido salta sobre el perro
perezoso. A raposa marrom répida
salta sobre 0 C50 preguieoso.
Step 4: Create a test application in Eclipse to do ocr on a pdf
Although Teseract only accepts tiff files, tess4j is able to convert pdfs to tiff. In order to enable this feature use the following steps:
a) Create a log4J properies file. The library that coverts pdfs to tiffs requires log4j. Log4j requires a properties file. Create a file named log4j.properties.txt in the directory in which you installed tess4J (in my case in C:\bin\Tess4J).
b) Add the following configuration:
log4j.rootLogger=debug, stdout, R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
# Pattern to output the caller's file name and line number.
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] (%F:%L) - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=example.log
log4j.appender.R.MaxFileSize=100KB
# Keep one backup file
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%nc) Create a new java class in tess4jTest named Testtess2 and add the following:
package Tess4jtest;
import java.io.File;
import net.sourceforge.tess4j.*;
public class Testtess2 {
public static void main(String[] args) {
org.apache.log4j.PropertyConfigurator.configure("C://bin//Tess4J//log4j.properties.txt"); // sets properties file for log4j
File image = new File("C:/bin/Tess4J/eurotext.pdf");
Tesseract tessInst = new Tesseract();
tessInst.setDatapath("C://bin//Tess4J");
try {
String result= tessInst.doOCR(image);
System.out.println(result);
} catch (TesseractException e) {
System.err.println(e.getMessage());
}
}
}
d) Run the application. You will get the following output:
INFO [main] (GhostscriptLoggerOutputStream.java:72) - GPL Ghostscript 9.09 (2013-08-21)
INFO [main] (GhostscriptLoggerOutputStream.java:72) - Copyright (C) 2012 Artifex Software, Inc. All rights reserved.
INFO [main] (GhostscriptLoggerOutputStream.java:72) - This software comes with NO WARRANTY: see the file PUBLIC for details.
INFO [main] (GhostscriptLoggerOutputStream.java:72) - Processing pages 1 through 1.
INFO [main] (GhostscriptLoggerOutputStream.java:72) - Page 1
The (quick) [brown] {fox} jumps!
Over the $43,456.78 <lazy> #90 dog
& duck/goose, as 12.5% of E-mail
from aspammer@website.com is spam.
Der ,,schnelle” braune Fuchs springt
?ber den faulen Hund. Le renard brun
«rapide» saute par-dessus le chien
paresseux. La volpe marrone rapida
salta sopra i] cane pigro. El zorro
marrén répido salta sobre el perro
perezoso. A raposa marrom répida
salta sobre 0 C50 preguieoso.
Step 5: Scan a text in another language.
Although the standard Tesseract implementation is capable of scanning non-English text, the results is better when using the right language files.
5.1: Download the following pdf (Grondwet1815) (the Dutch constitution of 1815).
5.2: Create a new java class named Testtess3 with the following content
package tess4jTest;
import java.io.File;
import net.sourceforge.tess4j.*;
public class Testtess3 {
public static void main(String[] args) {
org.apache.log4j.PropertyConfigurator.configure("C://bin//Tess4J//log4j.properties.txt"); // sets properties file for log4j
File image = new File("C:/$User/atach/Grondwet1815.pdf"); // <== make sure to use the path of the downloaded pdf.
Tesseract tessInst = new Tesseract();
tessInst.setDatapath("C://bin//Tess4J");
tessInst.setLanguage("nld"); // <<== set language to Dutch
try {
String result= tessInst.doOCR(image);
System.out.println(result);
} catch (TesseractException e) {
System.err.println(e.getMessage());
}
}
}
5.3: Run the application.
The debug information will show some warnings like those shown below. Don’t worry abut these. After 1-3 minutes, the entire Dutch constitution from 1815 (23 pages) will be shown. Don’t get confused if you don’t understand the content…. native speakers like me don’t understand it either 🙂
INFO [main] (GhostscriptLoggerOutputStream.java:72) - Page 23 ERROR [main] (GhostscriptLoggerOutputStream.java:72) - **** Warning: Encoding not present. ERROR [main] (GhostscriptLoggerOutputStream.java:72) - **** Warning: Encoding not present. ERROR [main] (GhostscriptLoggerOutputStream.java:72) - ERROR [main] (GhostscriptLoggerOutputStream.java:72) - **** This file had errors that were repaired or ignored. ERROR [main] (GhostscriptLoggerOutputStream.java:72) - **** The file was produced by: ERROR [main] (GhostscriptLoggerOutputStream.java:72) - **** >>>> GNU Ghostscript 7.05 <<<< ERROR [main] (GhostscriptLoggerOutputStream.java:72) - **** Please notify the author of the software that produced this ERROR [main] (GhostscriptLoggerOutputStream.java:72) - **** file that it does not conform to Adobe's published PDF ERROR [main] (GhostscriptLoggerOutputStream.java:72) - **** specification. ERROR [main] (GhostscriptLoggerOutputStream.java:72) -
Step 6: Get details on the scanned text
Up until now, we used tess4J high level API to get the scanned text. This results in a UDF8 encoded string. But what if you need more information on the scanned words, like the position, the scanning accuracy, if the word is underlined, bold or italic? In that case you need to use the low level tess4J API. In this step we will create a java program that will provide you with a list of all words found during a scan including all possible details.
6.1: Create a new java class named Testtess5 with the following content
package tess4jTest;
import static net.sourceforge.tess4j.ITessAPI.TRUE;
import java.awt.image.BufferedImage; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.nio.ByteBuffer; import java.nio.IntBuffer;
import javax.imageio.ImageIO;
import com.sun.jna.NativeLong; import com.sun.jna.Pointer;
import net.sourceforge.tess4j.*; import net.sourceforge.tess4j.ITessAPI.ETEXT_DESC; import net.sourceforge.tess4j.ITessAPI.TessBaseAPI; import net.sourceforge.tess4j.ITessAPI.TessPageIterator; import net.sourceforge.tess4j.ITessAPI.TessPageSegMode; import net.sourceforge.tess4j.ITessAPI.TessResultIterator; import net.sourceforge.tess4j.ITessAPI.TimeVal; import net.sourceforge.tess4j.util.ImageIOHelper; import net.sourceforge.tess4j.util.PdfUtilities;
public class Testtess5 {
public static void main(String[] args) {
String datapath = "C://bin//Tess4J";
String language = "eng";
TessBaseAPI handle = TessAPI1.TessBaseAPICreate();
File pdf = new File("C:/bin/Tess4J/eurotext.pdf");
File tiff = new File("C:/$User/atach/tmp.tif");
try {
tiff = PdfUtilities.convertPdf2Tiff(pdf);
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
BufferedImage image = null;
try {
image = ImageIO.read(new FileInputStream(tiff));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
ByteBuffer buf = ImageIOHelper.convertImageData(image);
int bpp = image.getColorModel().getPixelSize();
int bytespp = bpp / 8;
int bytespl = (int) Math.ceil(image.getWidth() * bpp / 8.0);
TessAPI1.TessBaseAPIInit3(handle, datapath, language);
TessAPI1.TessBaseAPISetPageSegMode(handle, TessPageSegMode.PSM_AUTO);
TessAPI1.TessBaseAPISetImage(handle, buf, image.getWidth(), image.getHeight(), bytespp, bytespl);
ETEXT_DESC monitor = new ETEXT_DESC();
TessAPI1.TessBaseAPIRecognize(handle, monitor);
TessResultIterator ri = TessAPI1.TessBaseAPIGetIterator(handle);
TessPageIterator pi = TessAPI1.TessResultIteratorGetPageIterator(ri);
TessAPI1.TessPageIteratorBegin(pi);
System.out.println("Bounding boxes:\nchar(s) left top right bottom confidence font-attributes");
int level = TessAPI1.TessPageIteratorLevel.RIL_WORD;
int height = image.getHeight();
do {
Pointer ptr = TessAPI1.TessResultIteratorGetUTF8Text(ri, level);
String word = ptr.getString(0);
TessAPI1.TessDeleteText(ptr);
float confidence = TessAPI1.TessResultIteratorConfidence(ri, level);
IntBuffer leftB = IntBuffer.allocate(1);
IntBuffer topB = IntBuffer.allocate(1);
IntBuffer rightB = IntBuffer.allocate(1);
IntBuffer bottomB = IntBuffer.allocate(1);
TessAPI1.TessPageIteratorBoundingBox(pi, level, leftB, topB, rightB, bottomB);
int left = leftB.get();
int top = topB.get();
int right = rightB.get();
int bottom = bottomB.get();
System.out.print(String.format("%s %d %d %d %d %f", word, left, top, right, bottom, confidence));
IntBuffer boldB = IntBuffer.allocate(1);
IntBuffer italicB = IntBuffer.allocate(1);
IntBuffer underlinedB = IntBuffer.allocate(1);
IntBuffer monospaceB = IntBuffer.allocate(1);
IntBuffer serifB = IntBuffer.allocate(1);
IntBuffer smallcapsB = IntBuffer.allocate(1);
IntBuffer pointSizeB = IntBuffer.allocate(1);
IntBuffer fontIdB = IntBuffer.allocate(1);
String fontName = TessAPI1.TessResultIteratorWordFontAttributes(ri, boldB, italicB, underlinedB,
monospaceB, serifB, smallcapsB, pointSizeB, fontIdB);
boolean bold = boldB.get() == TRUE;
boolean italic = italicB.get() == TRUE;
boolean underlined = underlinedB.get() == TRUE;
boolean monospace = monospaceB.get() == TRUE;
boolean serif = serifB.get() == TRUE;
boolean smallcaps = smallcapsB.get() == TRUE;
int pointSize = pointSizeB.get();
int fontId = fontIdB.get();
System.out.println(String.format(" font: %s, size: %d, font id: %d, bold: %b,"
+ " italic: %b, underlined: %b, monospace: %b, serif: %b, smallcap: %b",
fontName, pointSize, fontId, bold, italic, underlined, monospace, serif, smallcaps));
} while (TessAPI1.TessPageIteratorNext(pi, level) == TRUE);
}
} The program will scan the eurotext.pdf that we used before.
6.2: Run the program. You will get an output as shown below:
Bounding boxes: char(s) left top right bottom confidence font-attributes The 105 66 178 97 90,493225 font: Times_New_Roman, size: 9, font id: 283, bold: false, italic: false, underlined: false, monospace: false, serif: true, smallcap: false (quick) 205 67 347 106 87,137253 font: Times_New_Roman, size: 9, font id: 283, bold: false, italic: false, underlined: false, monospace: false, serif: true, smallcap: false [brown] 376 69 528 109 89,419556 font: Times_New_Roman, size: 9, font id: 283, bold: false, italic: false, underlined: false, monospace: false, serif: true, smallcap: false
It show that the word 'The' was found on a box with the coordinates 105,66 (left top), 178,97 (right bottom). The OCR result has a confidance of 90,49%. Furthermore the output contains information on the font and the text attributes.
Creating and testing restful services descriptors
How to create restful services descriptions and use these to generate mocks……
Building a Restful JSON services using Java
Hands-on description on building a simple Restful service using the Jersey framework and the Jackson libraries…..