The Model Context Protocol (MCP) takes the world by storm….. in this document both the concepts as well as the practical use are covered.
!!WORK IN PROGRESS!!
Introduction
The Model Context Protocol (MCP) was introduced by Anthropic only a few months ago (November 2024) as the ‘USB adaptor for AI’. It took the world by storm. It was almost immediately adopted by many vendors. A current search on the term MCP will provide you with thousands of hits. Unfortunately, though, getting to understand MCP within this overload of information is not necessarily straightforward. Many sources either focus on the concepts in very high-level terms (like ‘the USB adaptor for AI’) or drill straight into the details by throwing code at you.
The aim of this document is to combine both points of view. First, I cover the concepts and try to define which problem is solved by MCP. Next to that a MCP server and an MCP Client/Agent are built using TypeScipt.
Large Language Models
A Large Language Model (LLM), is an AI system designed to understand, generate, and interact with human language. At its core, an LLM is a very large and complex neural network, generated by indexing large parts of the Internet. We are all familiar with LLMs. These are the models used by Microsoft (ChatGPT), Google (Gemini) , Anthropic (Claude) and others that answer natural language questions, generate code, and translate text.
The neural networks are trained using all kinds of unstructured data available on the Internet. LLMs are very good at at answering ‘free format questions’ for which the answer is stored in some unstructured text in some public resource on the Internet. The model is not so good at answering questions that depend on ‘structured data’ (stored in databases). If you raise the following question in Gemini “Can you provide me with an overview of all published legal judgments regarding environmental violations in which the municipality of <X> played a role?”. You will not get a precise answer, for the simple reason that (apparently) Google has no access to the public database with Dutch rulings (that is available on the Internet). You will face similar challenges if you ask Gemini to provide you with a list of customers from your employer who have a revenue of more than 1 million euros and filed at least 2 service requests in the last month. This information is probably somewhere available in the databases of your organization, but for obvious reasons Google has no access to it :-).
The problem that MCP solves
This is where MCP comes in. MCP makes it possible to query structured data using natural language. Organisations collected large amounts of structured data in databases and/or accessible via APIs, SOAP services message-based services etc.. MCP enables organisations to make this data available in an AI system. This may mean that the data becomes publicly available, but more likely, the data needs to be accessible within your organization only. You may argue: why putting effort into making structured data available in an AI system if the data is already available using some sort of (internal) system? The reason for that is AI systems allow you to use natural language instead of using some kind of custom GUI to access the data. Next to that: if you make multiple data sources available in your AI system, you may be able to combine the data. If you have an API that serves hotels and an API that serves flights you should be able to ask your AI system: ‘book a flight and a hotel to Amsterdam next Monday’.
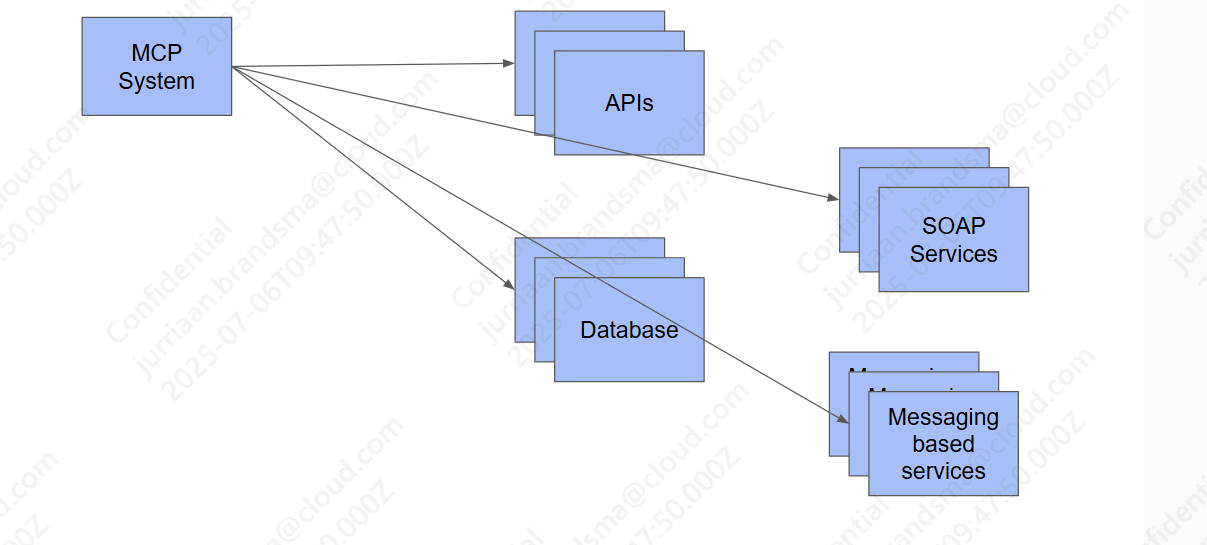
The MCP server
As can be seen in Figure 1, an MCP system makes available existing structured data sources for use in an AI system. It does so in a so-called MCP server. The task of an MCP server is twofold:
- It makes available a definition of the data sources that are available for the AI system. This definition is somewhat comparable to an Open API Specification (OAS) (Swagger) used for APIs or a WSDL used for SOAP services. The definition of an MCP server can be queried by an AI system (to find out what kind of data sources are exposed and how these can be used).
- It allows an AI system to call the available data sources. Calling the data sources (of whatever type) takes place in a standardised way defined by the MCP standard.
The definition exposed by an MCP server consists of three parts:
Tools
- Tools. These are active operations or functions that it can perform including the expected input and output. A tool may for example expose an resource of an API or the option to carry out an SQL query on a database.
Example: let’s say you want to expose a tool that takes two numbers (a and b) and adds these. The tool definition in that case will look like this:
server.tool(
"add",
"Use this tool to add two numbers together.",
{
a: z.number().describe("The first number to add"),
b: z.number().describe("The second number to add"),
},
async ({ a, b }) => {
return {
content: [
{
type: "text",
text: `${a + b}`,
},
],
};
}
);- The definition consists of the following parts:
"add": This is the name of the MCP tool. This is the identifier that an AI model would use when it decides to invoke this specific capability (e.g., if it needs to add two numbers)."Use this tool to add two numbers together.": This is the description of the MCP tool. It provides a human-readable explanation of what the tool does. This description is crucial for the AI model to understand the tool’s purpose and when it’s appropriate to use it in response to a user’s request.
{ a: z.number().describe("The first number to add"), b: z.number().describe("The second number to add"), }: This defines the input schema for the tool’s parameters.z.number().describe(...)indicates the use of a schema validation library (like Zod), which allows developers to define the expected types and add descriptions for each input parameter programmatically. When the MCP server publishes this tool’s definition, this part would be converted into a standard JSON Schema object, specifying that the tool expects two numerical inputs,aandb, along with their descriptions. The AI model would then understand what arguments it needs to provide when calling this tool.async ({ a, b }) => { return { content: [ { type: "text", text:${a + b}, }, ], }; }: This is the handler function (or implementation logic) of the tool.
"Use this tool to add two numbers together.": This is the description of the MCP tool. It provides a human-readable explanation of what the tool does. This description is crucial for the AI model to understand the tool’s purpose and when it’s appropriate to use it in response to a user’s request.
Resources
- Resources: This contains contextual (read only) information regarding the tools. It may for example contain contstants. Let’s say that you offer a tool that looks op the weather conditions for airports. The resouces may in that case contain a list of airports name abriviations and the geographical city they are located in. In the example below the resource defines a function to provides the schema of a database that consists of customers and sales. This is a common way to define a resource in case the tool is an SQL query.
server.resource(
"get_customer_sales_schema", // The unique name of the resource
"Retrieves the schema (tables, columns, and relationships) for the customer and sales data.", // A human-readable description
{}, // Input schema is empty as no parameters are needed to retrieve the full schema
async () => {
// This is the handler function that gets executed on the MCP server
// when an AI requests this resource.
// The database schema is defined statically within this handler.
const databaseSchema = {
tables: [
{
name: "Customers",
description: "Stores information about individual customers.",
columns: [
{
name: "customer_id",
dataType: "INT",
isPrimaryKey: true,
isForeignKey: false,
nullable: false,
description: "Unique identifier for the customer."
},
{
name: "first_name",
dataType: "VARCHAR(50)",
isPrimaryKey: false,
isForeignKey: false,
nullable: false,
description: "Customer's first name."
},
{
name: "last_name",
dataType: "VARCHAR(50)",
isPrimaryKey: false,
isForeignKey: false,
nullable: false,
description: "Customer's last name."
},
{
name: "email",
dataType: "VARCHAR(100)",
isPrimaryKey: false,
isForeignKey: false,
nullable: false,
description: "Customer's email address (unique)."
},
{
name: "registration_date",
dataType: "DATETIME",
isPrimaryKey: false,
isForeignKey: false,
nullable: false,
description: "Date when the customer registered."
}
]
},
{
name: "Sales",
description: "Records individual sales transactions.",
columns: [
{
name: "sale_id",
dataType: "INT",
isPrimaryKey: true,
isForeignKey: false,
nullable: false,
description: "Unique identifier for the sales transaction."
},
{
name: "customer_id",
dataType: "INT",
isPrimaryKey: false,
isForeignKey: true,
referencesTable: "Customers",
referencesColumn: "customer_id",
nullable: false,
description: "Foreign key linking to the Customers table."
},
{
name: "sale_date",
dataType: "DATETIME",
isPrimaryKey: false,
isForeignKey: false,
nullable: false,
description: "Date and time of the sale."
},
{
name: "amount",
dataType: "DECIMAL(10,2)",
isPrimaryKey: false,
isForeignKey: false,
nullable: false,
description: "Total amount of the sale."
},
{
name: "product_sku",
dataType: "VARCHAR(50)",
isPrimaryKey: false,
isForeignKey: false,
nullable: false,
description: "SKU of the product sold."
}
]
}
],
relationships: [
{
fromTable: "Sales",
fromColumn: "customer_id",
toTable: "Customers",
toColumn: "customer_id",
type: "Many-to-One",
description: "Each sale is associated with one customer."
}
]
};
// Return the structured database schema.
return {
content: [
{
type: "json", // Specify the content type as JSON
value: databaseSchema // The actual schema data
}
]
};
}
);Please mind that in the resource definition above both the schema from the ‘customer’ as well as from the ‘sales’ table are defined. Next to that the relation between the customer and sales table is defined. This information is required to generate SQL queries out of natural langue.
Promps
- Prompts. These are workflow templates that explain a LLM how to combine tools. In the following example we assume that we have two resources: a flights service and an hotel service. The prompt definition below helps the AI system to gather all information required to book a flight + hotel in one go. It also provides hints on what information to show to the traveler. Finally (and this is the most important part): it instructs the AI system on which tools to run based on the input gathered.
server.prompt(
"plan_flight_and_hotel_trip", // The unique name of this workflow prompt
"Guides the AI to plan a trip by searching for flights and hotels based on user criteria.", // A human-readable description
{
// Input schema for the overall trip planning request.
origin: z.string().describe("The departure city or airport code for the flight."),
destination: z.string().describe("The arrival city or airport code for the flight, and the city for the hotel."),
departure_date: z.string().describe("The desired departure date for the flight (YYYY-MM-DD)."),
return_date: z.string().describe("The desired return date for the flight (YYYY-MM-DD)."),
num_travelers: z.number().int().min(1).describe("The number of adults traveling."),
hotel_check_in_date: z.string().optional().describe("Optional: The desired hotel check-in date (YYYY-MM-DD). Defaults to departure_date if not provided."),
hotel_check_out_date: z.string().optional().describe("Optional: The desired hotel check-out date (YYYY-MM-DD). Defaults to return_date if not provided."),
num_rooms: z.number().int().min(1).optional().describe("Optional: The number of hotel rooms required. Defaults to 1 if not provided."),
},
async (params) => {
// This handler doesn't directly perform actions but constructs the prompt
// that guides the AI's reasoning and tool/resource usage.
// Default hotel dates if not explicitly provided
const checkInDate = params.hotel_check_in_date || params.departure_date;
const checkOutDate = params.hotel_check_out_date || params.return_date;
const numRooms = params.num_rooms || 1;
// The 'template' defines the structured conversation that guides the AI.
return {
template: [
{
role: "system",
content: `You are a travel planning assistant. Your goal is to find suitable flights and hotels based on user criteria.
1. **Gather Details:** Confirm all necessary flight and hotel information.
2. **Search & Combine:** Use the 'Flights' and 'Hotels' tools.
3. **Present Plan:** Synthesize results into a clear travel plan. If issues arise, state them and suggest alternatives.
Think step-by-step and show your reasoning before calling any tools.`
},
{
role: "user",
content: `I need to plan a trip.
Origin: {{origin}}
Destination: {{destination}}
Departure Date: {{departure_date}}
Return Date: {{return_date}}
Number of Travelers: {{num_travelers}}
{{#if hotel_check_in_date}}Hotel Check-in Date: {{hotel_check_in_in_date}}{{/if}}
{{#if hotel_check_out_date}}Hotel Check-out Date: {{hotel_check_out_date}}{{/if}}
{{#if num_rooms}}Number of Rooms: {{num_rooms}}{{/if}}
Please start by planning the trip.`
},
{
role: "assistant",
content: `Okay, I'm planning your trip from {{origin}} to {{destination}}, departing on {{departure_date}} and returning on {{return_date}}, for {{num_travelers}} traveler(s).
For the hotel, I will look for accommodations in {{destination}} from ${checkInDate} to ${checkOutDate}, for ${numRooms} room(s).
**Planning Steps:**
1. **Gathering Details:** Confirmed all necessary information.
2. **Searching for Flights and Hotels:**
I will now use the 'Flights' and 'Hotels' tools to find options.
<tool_code>
console.log(await Flights.search_flights({
origin: "{{origin}}",
destination: "{{destination}}",
departure_date: "{{departure_date}}",
return_date: "{{return_date}}",
num_travelers: {{num_travelers}}
}));
console.log(await Hotels.search_hotels({
location: "{{destination}}",
check_in_date: "${checkInDate}",
check_out_date: "${checkOutDate}",
num_rooms: ${numRooms},
num_guests: {{num_travelers}}
}));
</tool_code>
3. **Presenting Your Travel Plan:**
[AI will synthesize flight and hotel results here, providing the combined travel plan or noting any issues.]
`
}
]
};
}
);This prompt, named "plan_flight_and_hotel_trip", is designed to guide an AI assistant through the process of planning a travel itinerary that includes both flights and hotels. It’s a structured way to ensure the AI gathers all necessary information, utilizes specific tools, and presents a coherent plan to the user.
Here’s a breakdown of its key components and how it works:
server.prompt(...): This is the method used in a JavaScript/TypeScript MCP SDK to define a new prompt."plan_flight_and_hotel_trip": This is the unique identifier for this prompt. When a user’s request aligns with trip planning, the AI or the orchestrating application would invoke this specific prompt."Guides the AI to plan a trip by searching for flights and hotels based on user criteria.": This is a human-readable description of the prompt’s purpose. It helps in documentation and potentially for other AIs or systems to understand what this prompt is for.
- Input Schema (
{ origin: z.string().describe(...), ... }):- This section defines the parameters that the AI (or the application interacting with the AI) needs to provide when initiating this prompt. These are the pieces of information required from the user to plan the trip.
- It uses a schema validation library (like Zod, indicated by
z.string(),z.number().int(), etc.) to specify data types, descriptions, and whether parameters are optional (.optional()). - Examples include
origin,destination,departure_date,return_date,num_travelers, and optional hotel-specific dates and room count.
- Asynchronous Handler (
async (params) => { ... }):- This is the function that gets executed on the MCP server when this
plan_flight_and_hotel_tripprompt is invoked. - It takes the
params(the input values provided according to the input schema). - Inside this handler, it calculates default values for
hotel_check_in_date,hotel_check_out_date, andnum_roomsif they weren’t explicitly provided by the user, ensuring the prompt has complete information for the hotel search. - The primary role of this handler is to construct the
template(the actual messages that will be sent to the underlying Large Language Model).
- This is the function that gets executed on the MCP server when this
template: [...]: This is the core of the prompt, defining the structured conversation that guides the AI’s reasoning and actions. It’s an array of message objects, each with aroleandcontent.- System Message (
role: "system"):- This message sets the overall instructions and persona for the AI. It outlines the high-level workflow steps:
- Gather Details: Confirming information.
- Search & Combine: Using tools.
- Present Plan: Synthesizing results.
- It also instructs the AI to “Think step-by-step and show your reasoning before calling any tools,” which is a common prompt engineering technique to encourage a more deliberate and transparent thought process from the LLM.
- This message sets the overall instructions and persona for the AI. It outlines the high-level workflow steps:
- User Message (
role: "user"):- This represents the initial input from the user (or the application acting on behalf of the user).
- It includes placeholders like
{{origin}},{{destination}}, etc., which will be dynamically filled with the actualparamsprovided when the prompt is invoked. - It explicitly asks the AI to “Please start by planning the trip,” initiating the workflow.
- Assistant Message (
role: "assistant"):- This message is pre-filled by the MCP prompt. It serves several purposes:
- Confirmation: It confirms the user’s input back to them.
- Workflow Guidance: It explicitly states the “Planning Steps” the AI will follow, aligning with the system instructions.
- Tool Invocation (
<tool_code>...</tool_code>): This is a critical part of the prompt. It embeds calls to other MCP tools (Flights.search_flightsandHotels.search_hotels). The AI is instructed to execute these tools.- The parameters for these tool calls (
origin,destination,departure_date, etc.) are also dynamically inserted from the prompt’s input parameters. - By placing both tool calls in a single assistant turn, the prompt encourages the AI to consider executing them in sequence or in parallel, and then move to the synthesis step.
- The parameters for these tool calls (
- Placeholder for Synthesis:
[AI will synthesize flight and hotel results here...]acts as a strong hint to the AI about what its next output should contain after the tool calls are (conceptually) executed and their results are made available to the LLM.
- This message is pre-filled by the MCP prompt. It serves several purposes:
- System Message (
Important: The above example is intended for an advanced AI system…. don’t get disincuraged if you don’t fully understand it. The important thing is to understand the function of tools, resources and prompts for now. No need to understand all details just yet….
The MCP Client and Agent
An MCP system typically consists of an MCP client, agent and server. In many documentation available on the internet only the MCP client and server ar mentioned. In these cases the client includes the agent as well.
The MCP Client
The role of the MCP client is to interact with the MCP server. The client is used to:
- Fetch information about the available tools, resources and prompts offered by an MCP server. This is important information for the AI system to be able to use the tools and to provide the right parameters to the tools.
- Call tools. In order to answer the natural language questions from users the AI system will need to call the tools. This task is carried out by the MCP client.
An MCP client and MCP server can communicate via either STDOUT or JSON-RPC 2.0 over HTTP (which comes close to Rest). STDOUT is usefull for testing purposes when server and client are on the same host. In practice JSON-RPC 2.0 over HTTP is almost always used for serious applications.
The MCP Agent
The one thing we haven’t discussed is the the role of the LLM in all of this. This is where the MCP agent comes in. The MCP agent does the following:
- When a natural language query comes in the MCP agent will send it the LLM (toghether with information offered by the MCP server). Based on that the LLM will determine which tools to call and what parameters to use.
- If the LLM instructs the MCP agent to call a tool, the MCP agent will forward this request to the client.
- If data comes back from a tool the agent will pass it on the LLM. The LLM wil interpret this data and may instruct a new call to a tool, or it may return the answer to the user query (in natural language).
- If the answer to the natural language query is received the agent will send it back the user.
As you can see the agent to a large extent plays the role of an orchestrator. In a traditional integration application one has to define the steps to be taken in order to answer a user query. The sequence in which API’s or database queries will be made needs to be defined (in code) in every possible detail. In an MCP system this is not the case. It is the agent who determines which steps to take, which tools to run, which parameters to use. It does so based on the instructions it gets from the LLM.
MCP Workflow
A typical MCP worflow consists of the following steps:
- Customer raises a natural language query
- The MCP Client will ask the MCP servers what kind of structured data they have to offer.
- The MCP Agent will send the natural language query and the information on the available structured data to an LMM. The LLM will give instructions on which structured data sources to consult
- The MCP Agent will ask the MCP Client to tell the MCP Server to get the requested data.
- The MCP Server will invoke the structure data source (using an SQL query, by doing an API call, by posting a message). The date received is send back to the MCP server and the MCP client.
- The MCP client will ask the MCP Agent to send the results of the query back to the LLM to make a natural language answer.
- The LLM will return the natural language answer which in turn will be returned to the consumer.
(*) Steps 3-6 may be repeated a number of times.
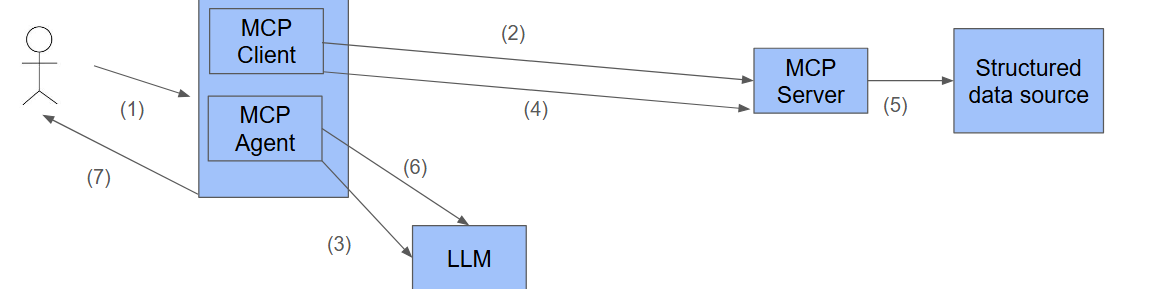
Important: As you can see, data is exchanged at least twice with the LLM. The LLM receives the question, detailed information about the MCP server configuration and more importantly: the results of the invocation of tools. If these tools offer non-public / confidential information, this could be an issue. Organisations may not be allowed to send this information to a public LLM. To avoid this security issue one can decide to use a private LLM. Free and paid LLMs are available.
In practice
So far the concepts. Time for some actual implementations. I created a number of tutorials that can help you to build your own MCP Server and MCP Client+Agent. The examples are built using TypeScript. In order to run the code it is advised to install:
- Visual Studio Code
- NodeJS (including npm)
- TypeScript (see instructions in the repositories)
- As a first step following the instructions to build an HTTP-enabled MCP Server. Using this tutorial you will create an MCP server that exposes one tool (to add two numbers).
- You could use your MCP server with an out-of-the-box tool like Claude Destop. This, nevertheless, doesn’t allow you to understand how an MCP system actually works. Therefore I would suggest to follow the tuturoal to build an MCP Client+Agent. This will put it together and make you understand how things work.
More information
If you would like to study MCP in more details, I would suggest the following resources:
The concepts
- The official documentation. A bit hard to read, but it does cover the concepts well.
Practical examples
- A good blog on building an MCP server in TypeScript. Also take a look at this video.
- Finding information on building an MCP client is generally hard. One of the few good sources I found is: “building an MCP client” as part of the official documentation.